A Rede Portuguesa de Data Stewards (RPDS), iniciativa integrada no Re.Data, acolhe um workshop dedicado ao desenvolvimento da metodologia de personas para data steward, organizado em colaboração com o Data Steward Careers Track Working Group da Research Data Alliance (RDA).
Este evento apresenta o conceito de personas aplicado à gestão de dados de investigação. Estes perfis semi-ficcionais procuram representar as motivações, necessidades e desafios mais comuns associados às funções de data steward, contribuindo para uma melhor compreensão destes perfis profissionais.
Através de atividades colaborativas, os participantes serão convidados a contribuir para a definição de personas que poderão apoiar instituições na descrição de funções, no desenvolvimento profissional, na estruturação de percursos formativos e na implementação de práticas de recursos humanos mais eficazes.
O workshop destina-se a profissionais envolvidos na gestão de dados de investigação ou com ligação direta a esta área.
A sessão será dinamizada por Liise Lehtsalu, da Research Data Alliance Association (RDA Europe), e terá lugar no dia 28 de maio, entre as 10h00 e as 12h00, em formato online e em língua inglesa.
A participação é gratuita, mediante inscrição prévia, sendo o número de vagas limitado.
O Re.Data esteve em destaque nas Jornadas FCCN 2026 com a apresentação do plano de atividades para 2026. Pedro Príncipe, coordenador do projeto pela Universidade do Minho, apresentou o trabalho em curso e as perspectivas de consolidação da Rede para o presente ano, destacando algumas das atividades em curso nos eixos de intervenção de políticas de GDI e curadoria de dados, e as ações previstas no programa de formação.
A intervenção permitiu dar a conhecer à comunidade os principais resultados alcançados e as linhas de desenvolvimento previstas para 2026, que continuam a ser asseguradas por um consórcio composto por Universidade do Minho (líder do consórcio e coordenador), Universidade de Coimbra (co-coordenador), Instituto Politécnico de Bragança, ISCTE – Instituto Universitário de Lisboa e Universidade Nova de Lisboa .
A presença nas Jornadas FCCN 2026 permitiu mostrar uma visão integrada do projeto e a sua relevância para o ecossistema nacional de gestão de dados de investigação, demonstrando as oportunidades e mais valias proporcionadas à comunidade: acesso a formação especializada e recursos de aprendizagem, integração numa comunidade nacional de prática, utilização de ferramentas, guias e recursos de dados FAIR, serviços de suporte contínuo, apoio à implementação de políticas institucionais, acesso a casos de uso e boas práticas.
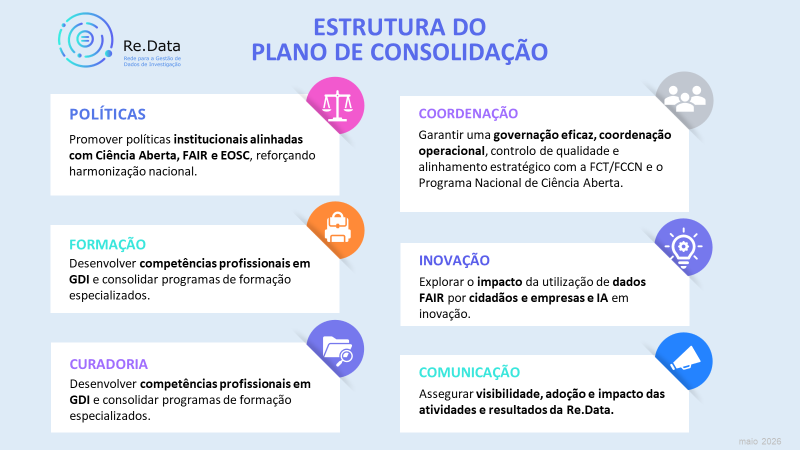
O plano de trabalhos está distribuído em três linhas de ação principais: i) Políticas e estratégias de Ciência Aberta e Gestão de dados de Investigação; ii: Formação, competências e Hub de capacitação; iii) Suporte à curadoria e publicação de dados. Estas linhas são complementadas com uma área transversal de Exploração da utilização de dados FAIR por cidadãos e empresas e IA em inovação. Estas linhas de ação são coordenadas por uma equipa que proporcionará uma estrutura de gestão eficaz e processos para o acompanhamento contínuo das tarefas, e apoiadas por um serviço de comunicação e disseminação, que atua como o ramo de comunicação e gestão de eventos do projeto e da Rede.
O Re.Data reafirma-se como uma iniciativa orientada para a capacitação, a colaboração e a melhoria contínua das práticas de dados abertos e FAIR em Portugal.
A presente sondagem foi enviada à Rede Portuguesa de Data Stewards (RPDS) no dia 03 de março de 2026, tendo sido reforçada com um lembrete a 04 de março de 2026.
O objetivo foi identificar áreas prioritárias de interesse e atuação no âmbito da gestão de dados de investigação.
Caracterização das respostas
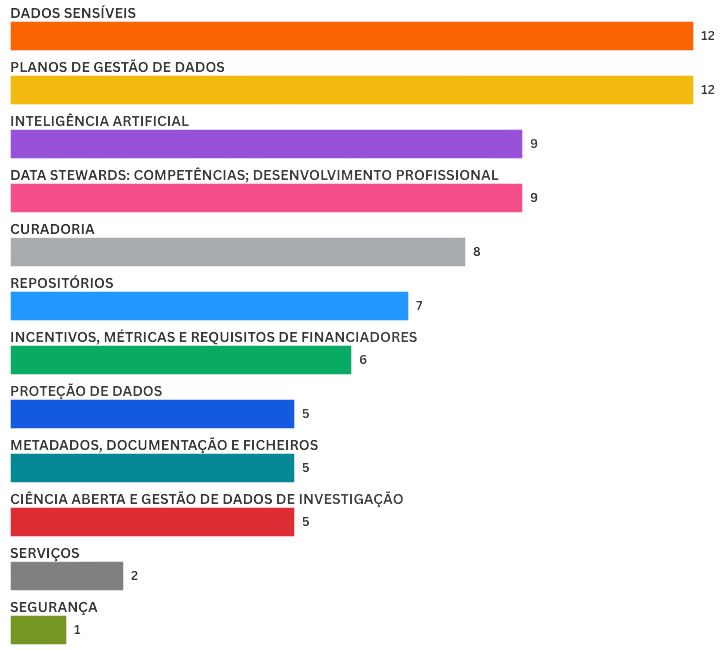
Total de respostas recebidas: 80
Respostas excluídas: 4 (por inconsistência ou invalidação)
Total de temas identificados: 81
Nota metodológica: algumas respostas incluíram múltiplos temas, tendo sido desdobradas para melhor análise.
Distribuição dos temas identificados
A análise realizada evidencia que os dois temas mais destacados correspondem às principais preocupações da comunidade: o tratamento de dados sensíveis e os planos de gestão de dados.
Adicionalmente, foram identificados temas de elevada relevância, nomeadamente, a inteligência artificial e o papel dos data stewards, em particular no que diz respeito às suas competências e desenvolvimento profissional.
Num nível intermédio, surgem tópicos como a curadoria de dados, os repositórios e os incentivos, métricas e requisitos de financiadores.
Assim, podemos destacar as seguintes conclusões:
A sensibilidade dos dados assume um papel central, evidenciando preocupações éticas, legais e operacionais.
Existe uma forte preocupação com a estruturação da gestão de dados, particularmente através de planos formais.
Verifica-se um interesse crescente na inteligência artificial e na profissionalização dos data stewards.
Algumas áreas críticas, como a segurança e serviços, poderão estar sub-representadas, sugerindo oportunidades para futura sensibilização.
Priority areas of interest and activity within RDM: survey
This survey was sent to the Portuguese Network of Data Stewards (RPDS) on 3 March 2026 and was followed up with a reminder on 4 March 2026.
The aim was to identify priority areas of interest and activity within the field of research data management.
Overview of responses
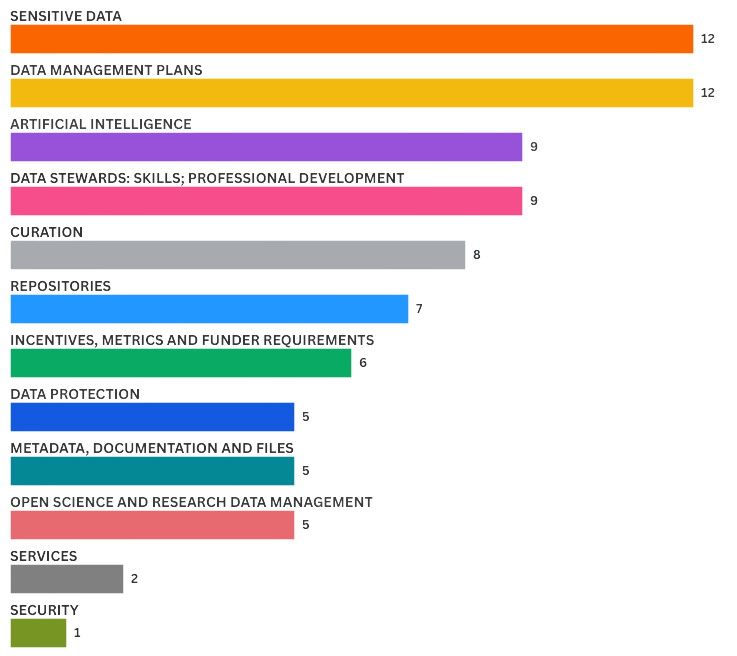
Total responses received: 80
Responses excluded: 4 (due to inconsistency or invalidation)
Total topics identified: 81
Methodological note: some responses included multiple topics and were therefore split to allow for more accurate analysis.
Distribution of identified topics
The analysis shows that the two most prominent topics reflect the main concerns of the community: handling sensitive data and data management plans.
In addition, the following highly relevant topics were identified: artificial intelligence and the role of data stewards, particularly with regard to their skills and professional development.
At an intermediate level, topics such as data curation, repositories, and incentives, metrics and funder requirements emerged.
Accordingly, the following conclusions can be drawn:
The sensitivity of data plays a central role, raising ethical, legal and operational concerns.
There is a strong focus on the structuring of data management, particularly through formal plans.
There is a growing interest in artificial intelligence and the professionalisation of data stewards.
Some critical areas, such as security and services, may be underrepresented, suggesting opportunities for raising awareness in the future.
A Rede Portuguesa de Data Stewards(RPDS) uma iniciativa do projeto Re.Data, promoveu uma sessão dedicada aos cadernos electrónicos de laboratório – Electronic Laboratory Notebooks (ELNs), confirmando o avanço de uma comunidade nacional articulada em torno destes instrumentos digitais de registo de investigação.
A investigadora, com vasta experiência em ELNs, no registo de processos, dados FAIR e tecnologias semânticas, sublinhou o facto da implementação de um ELN ir muito além da aquisição de licenças, pois exige tempo, planeamento e uma forte aposta na adesão e capacitação dos utilizadores . Na sua apresentação, explorou estratégias práticas para envolver as equipas, garantir formação contínua e apoiar o uso quotidiano dos sistemas, de forma a que o ELN se torne uma parte integrante e útil da prática laboratorial .
O contributo de Samantha Pearman‑Kanza sobre a adoção de ELNs é particularmente relevante num momento em que as instituições e equipas nacionais começam a consolidar práticas e a trocar experiências de implementação.
Estas iniciativas, que se irão repetir ao longo deste ano, mostram como o ecossistema português está a estruturar redes, recursos e formação específica para apoiar a adoção sustentada de cadernos electrónicos de laboratório.
This session will focus on Electronic Laboratory Notebooks (ELNs), highlighting national initiatives: active working group/ community-building effort in this area and international perspectives on adopting ELNs in research environments.
Agenda
Opening & Welcome – Portuguese Data Stewards Network (RPDS)
Ongoing National Activities on Electronic Laboratory Notebooks -Working Group on Training and Skills for FAIR Data Management (André Viera – University of Minho); –eLabFTW Portugal Community (Maria Paola Tomasino – CIIMAR. UP)
International Prospective: “One Does Not Simply ‘Adopt’ an ELN” (Samantha Pearman-Kanza – University of Southampton)
Discussion & Q&A
Closing Remarks
One Does Not Simply ‘Adopt’ an ELN. Abstract : Implementing Electronic Lab Notebooks (ELNs) is a complex and time‑intensive process that involves far more considerations than simply purchasing licenses. One of the most frequently overlooked components of this process is user adoption. Even the most advanced and well‑configured ELN will fail to deliver value if users are not effectively engaged, trained, and supported throughout the implementation and beyond. This talk will explore key considerations and practical strategies for fostering successful user adoption of ELNs, ensuring that the system becomes an integrated and beneficial part of laboratory practice.
Dr Samantha Pearman-Kanza (University of Southampton) -Short Bio: Dr. Samantha Pearman-Kanza is a Principal Enterprise Fellow at the University of Southampton, the Principal Investigator for the Careers and Skills for Data-driven Research Network (CaSDaR), , the Pathfinder Lead on Process Recording for the Physical Sciences Data Infrastructure (PSDI) Initiative – www.psdi.ac.uk, and a researcher for the AI in Chemistry Hub (AIChemy – www.aichemy.ac.uk). Samantha sits on the Advisory Boards for the Future Labs Live (Basel) and London Labs Live (UK) Conferences, the Machines Learning Chemistry Project (University of Nottingham), the STEP-UP project (Imperial College London), and the Knowledger Project (University of North Florida), and the UK electronic information Group (UKeiG) STRIX Committee. She is also the Faculty Deputy Chair of the Ethics Committee and sit on the Steering Committee for our brilliant Chemistry and Chemical Engineering Enterprise Solutions. Samantha’s key research areas are ELNs, process recording, FAIR data, data stewardship and research data management, and semantic web technologies.
As redes europeias de data stewards estão a consolidar-se como estruturas essenciais para apoiar a gestão de dados de investigação num ecossistema científico cada vez mais orientado para os princípios FAIR e para a Ciência Aberta. Em vários países, estas redes assumem um papel estratégico na capacitação de profissionais, no desenvolvimento de políticas e na criação de infraestruturas de suporte. Entre estas iniciativas, a Rede Portuguesa de Data Stewards tem-se afirmado como um exemplo particularmente dinâmico e em rápido desenvolvimento, recebendo crescente visibilidade em eventos e relatórios internacionais.
🌍 Um movimento europeu em expansão
A criação de redes nacionais de data stewards tem sido impulsionada por iniciativas europeias ligadas à Ciência Aberta, com destaque para projetos como o EOSC Focus e grupos especializados como o Professionalising Data Stewardship Interest Group da Research Data Alliance. Este grupo coordena várias task groups dedicadas a temas fundamentais, incluindo perfis profissionais, carreiras, formação, certificação e redes de conhecimento como a TG7, centrada precisamente em networking e troca de experiências entre data stewards a nível internacional.
Em paralelo, países como a Irlanda têm investido na criação de redes formais, como a Sonraí – Irish Data Stewardship Network, estabelecida com financiamento nacional e cujo objetivo é consolidar competências e desenvolver o ecossistema FAIR de forma sustentável.
Estas iniciativas mostram que a profissionalização da gestão de dados deixou de ser um tema emergente para se tornar uma prioridade estrutural no panorama europeu de investigação.
Portugal assume destaque crescente na área
A Rede Portuguesa de Data Stewards tem vindo a destacar-se pela sua organização, visibilidade e capacidade de mobilização da comunidade nacional. Formalizada no contexto das atividades Re.Data, a rede integra profissionais de diversas instituições e tem ganho relevância através de apresentações em eventos europeus e da produção de documentos estruturantes.
🤝 Cooperação entre redes: o valor da internacionalização
A ligação entre redes nacionais é promovida, entre outros espaços, pela TG7 do grupo da RDA, que atua como ponto de encontro para comunidades internacionais de data stewards.
A partilha de práticas, o desenvolvimento de materiais comuns e o reconhecimento mútuo de competências têm permitido fortalecer a identidade profissional dos data stewards e acelerar a adoção de práticas FAIR.
Nesse contexto, a atuação portuguesa tem sido reconhecida, integrando discussões, contribuindo para relatórios, exemplos abaixo, e acolhendo iniciativas de disseminação que elevam o perfil da rede a nível europeu.
Sharma, C. J. M., Holmstrand, K. F., Rauste, P., Ekman, O., Rebernig-Hedman, C. A., Fogtmann-Schulz, A., Drachen, T. M., Vlachos, E., CALDONI, G., Boavida, C. P., Eerland, A., Brinkman, L., Pasquale, V., Osmenaj, E., Rainer, H., Ritschard, E., & Kiesel, M. (2025). M6.2 New Professional Networks.
A Rede Portuguesa Da Data Stewards continua a crescer, contando já com 107 membros em todo o país, e destacou-se em 2025 com a realização de um workshop nacional sobre ELNs, um inquérito nacional aos profissionais de apoio à gestão de dados e a apresentação pública de um perfil emergente de competências para data stewards.
Para 2026, estão previstas cinco sessões temáticas, incluindo um evento pré‑Fórum GDI, sendo que a próxima, em março, será dedicada aos electronic laboratory notebooks.
O Workshop Re.Data 2026 promovido pela Rede Nacional para a Gestão de Dados de Investigação, reuniu dezenas de profissionais e decisores para refletir sobre o futuro da gestão de dados de investigação em Portugal, num evento integrado na Love Data Week, sob o mote “Dados FAIR, Inteligência Artificial e Serviços GDI em Portugal”. Este workshop correspondeu também à 4ª Reunião da Assembleia Geral do Consórcio Re.Data, Centros GDI & FCT-FCCN, funcionando como reunião aberta à comunidade. O evento ocorreu em modo presencial, mas teve difusão simultânea, online.
A sessão de abertura contou com as intervenções da Reitoria da Universidade do Minho, na pessoa do vice-Reitor António Salgado, da coordenação do Consórcio Re.Data, representado por Pedro Príncipe e de João Nuno Ferreira, vice-Presidente da FCT, sublinhando a importância estratégica dos dados FAIR, da Ciência Aberta e da criação de infraestruturas sustentáveis para suportar o ecossistema científico nacional.
Em destaque esteve a apresentação de Vyacheslav “Slava” Tykhonov, chefe de Interoperabilidade e Inteligência Artificial na CODATA, coautor do padrão emergente Croissant para Machine Learning, tendo demonstrado o seu potencial nos desafios da gestão de dados FAIR nas infraestruturas de dados de investigação. Evidenciou como dados bem descritos e interoperáveis são a base para uma inteligência artificial mais robusta e responsável.
Houve espaço para discussão e perguntas, moderado por Eloy Rodrigues, Director dos Serviços de Documentação da Universidade do Minho
Os resultados do projeto Re.Data e perspetivas futuras foram apresentados, estimulando uma reflexão conjunta, focando os três pilares deste projeto: políticas, formação e curadoria. Foram destacados os recursos produzidos para toda a comunidade, no âmbito do projeto, disponíveis no Website, naComunidade Re.Data do repositório Zenodo e no canal YouTube.
A equipa da FCT | FCCN apresentou osnovos serviços nacionais: POLEN DataHub, o POLEN Blueprint e o POLEN Sync.
OsCentros de competênciasGDI apoiados pela FCT, apresentaram alguns dados de impacto nas suas instituições, com políticas aprovadas, criação de repositórios e serviços de dados, oferta formativa robusta, redes internas de data stewards e datasets FAIR publicados, evidenciando uma mudança cultural na forma como os dados são planeados, preservados, partilhados e reutilizados.
No final do evento, houve mais uma vez espaço para discussão dos temas e esclarecimento de perguntas colocadas pela audiência presencial e online, tendo sido moderada por Paula Moura, dos Serviços de Documentação e Bibliotecas da Universidade do Minho.
O Workshop Re.Data 2026 encerrou com uma mensagem clara:
Portugal dispõe, hoje, de condições para estabelecer uma rede participativa e sustentável, capaz de ligar dados e pessoas, consolidar serviços nacionais e posicionar a comunidade científica para tirar partido da inteligência artificial com dados mais abertos, mais bem documentados e verdadeiramente FAIR.
A Rede Nacional para a Gestão de Dados de Investigação – Re.Data, promove, um evento internacional onde serão apresentados os resultados do Programa Nacional de Ciência Aberta e Dados Abertos de Investigação (PNCA e DAI), discutidos os desafios da gestão de dados FAIR e o papel da Inteligência Artificial nas infraestruturas de dados de investigação. Contará com a presença de Simon Hodson(Executive Director da CODATA) eVyacheslav (Slava) Tykhonov (Head of Interoperability and Artificial Intelligence na CODATA)
11h00-11h30 | Abertura e introdução [apresentação]
António Salgado, Vice-reitor para Investigação e Política Científica da Universidade do Minho.
Pedro Príncipe, Chefe de Divisão nos Serviços de Documentação e Bibliotecas da Universidade do Minho, Coordenador do Consórcio Re.Data.
João Nuno Ferreira, Vice-Presidente da Fundação para a Ciência e a Tecnologia e Coordenador Geral da Unidade de Computação Científica Nacional da FCT.
11h30-12h30 | Desafios da gestão de dados FAIR e a Inteligência Artificial nas infraestruturas de dados de investigação, utilizando o formato Croissant para Machine Learning, Simon Hodson (Executive Director da CODATA) e Vyacheslav (Slava) Tykhonov (Head of Interoperability and Artificial Intelligence na CODATA) [apresentação]
Moderador: Eloy Rodrigues, Diretor dos Serviços de Documentação e Bibliotecas da Universidade do Minho.
12h30-13h00 | Resultados do projeto Re.Data e perspetivas futuras: políticas, formação e curadoria, Pedro Príncipe (Universidade do Minho), Inês Caramelo (Universidade de Coimbra), Maria Tomasino (CIIMAR-UP) , Daniel Alvese Cátia Carvalho (NOVA FCSH), André Vieira (Universidade do Minho) – Consórcio Re.Data. [apresentação]
13h00-14h00 | Almoço
14h00-14h45 | Novos serviços POLEN para dados de investigação: POLEN Blueprint, POLEN DataHub, POLEN Sync, Filipa Pereira, Pedro Sobral, e Sara Pestana, FCCN – Serviços Digitais da FCT [apresentação]
14h45-15h30 | Centros de competênciaem Gestão de Dados de Investigação: impacto e resultados
Moderador: Paula Moura, Serviços de Documentação e Bibliotecas da Universidade do Minho.
15h30-16h00| Encerramento
Nota: este workshop corresponde à 4ª Reunião da Assembleia Geral do Consórcio Re.Data, Centros GDI & FCT-FCCN – funcionando como reunião aberta à comunidade.
O projeto mobilizou centenas de participantes de vários pontos do país para sessões intensivas de formação, nomeadamente, workshops, bootcamps, webinars. Foi ultrapassada a marca dos 1500 participantes nas séries de webinars. Estes números reforçam o papel do Re.Data como referência nacional na capacitação em Ciência Aberta (CA) e Gestão de Dados de Investigação (GDI).
O programa de especialização profissional para curadores de dados, gestores de repositórios e data stewards destacou-se como um dos eixos centrais, contribuindo para a profissionalização de perfis-chave na infraestrutura nacional de GDI. Neste, enquadram-se as duas edições do Workshop de fundamentos da curadoria de dados – especialização para bibliotecários de dados e profissionais de informação, o Workshop dedicado a questões jurídicas, proteção de dados e licenças e o Bootcamp de formação de Data Stewards, reunindo mais de 130 participantes, selecionados entre cerca de duas centenas de candidaturas.
Na vertente de formação de formadores, o Re.Data organizou o Bootcamp de Formação de Formadores em Ciência Aberta e o Workshop de Instrutores de Data Stewards, capacitando vários profissionais no território nacional, que se propuseram a replicar a oferta formativa recebida nas instituições de ensino superior e centros de investigação.
Entre Coimbra e Bragança, estas iniciativas envolveram mais de 60 participantes, selecionados de um total de 94 inscritos, que passam agora a integrar um núcleo estratégico de formadores alinhado com o desenvolvimento da Rede Portuguesa de Data Stewards, prevista no roteiro como estrutura de suporte continuado à comunidade.
Para investigadores, doutorandos e coordenadores de projeto, o ReData promoveu um plano de workshops sobre utilização de cadernos de laboratório eletrónicos, boas práticas de gestão de dados, publicação de dados FAIR por áreas disciplinares e conhecimentos de integridade e ética na gestão e partilha de dados. Os dados de monitorização apontam para mais de 600 inscrições, com um total de cerca de 450 participantes efetivos nestas ações, evidenciando uma procura crescente por competências em planeamento da gestão de dados, preparação e publicação de dados FAIR e tratamento de dados sensíveis ao longo do ciclo de vida da investigação.
Osciclos de webinars temáticos foram determinantes para alargar o alcance do Re.Data, contando com cerca de 1800 inscrições, das quais se efetivaram mais de 1500 participações. Destacam-se a série de webinars Love Data Week, as séries sobre novos perfis e competências – Open Access Week e a série que abordou a proteção de dados em projetos de investigação.
Estes números sustentam a próxima fase de implementação: o lançamento de dois MOOCs (massive open online courses) – em dados FAIR e dados sensíveis – na plataforma NAU e o crescimento contínuo do Skills Builder Hub, que irá agregar dezenas de recursos de aprendizagem, casos de uso, tutoriais e ferramentas, para apoiar as boas práticas de GDI.
Este grande número de iniciativas concretizadas, em parceria com o elevado volume de participantes coloca o projeto numa posição privilegiada na capacitação da comunidade em CA e GDI, em Portugal, bem como na preparação de instrutores preparados para replicarem juntos dos seus investigadores e unidades de investigação e desenvolvimento, as melhores práticas de GDI.
Em paralelo com a dinamização da Rede Portuguesa de Data Stewards, na realização de reuniões da Assembleia Geral com os centros de competência financiados pela FCT-FCCN e na organização de InfoSessions sobre a EOSC(European Open Science Cloud) reforça o cumprimento das metas de governança e apoio às redes nacionais, previstos para 2025.
No âmbito da missão do Re.Data, que visa apoiar as atividades de gestão de dados de investigação (GDI), um dos serviços implementados é o serviço de helpdesk, que complementa os materiais de suporte que têm vindo a ser disponibilizados no âmbito do projeto.
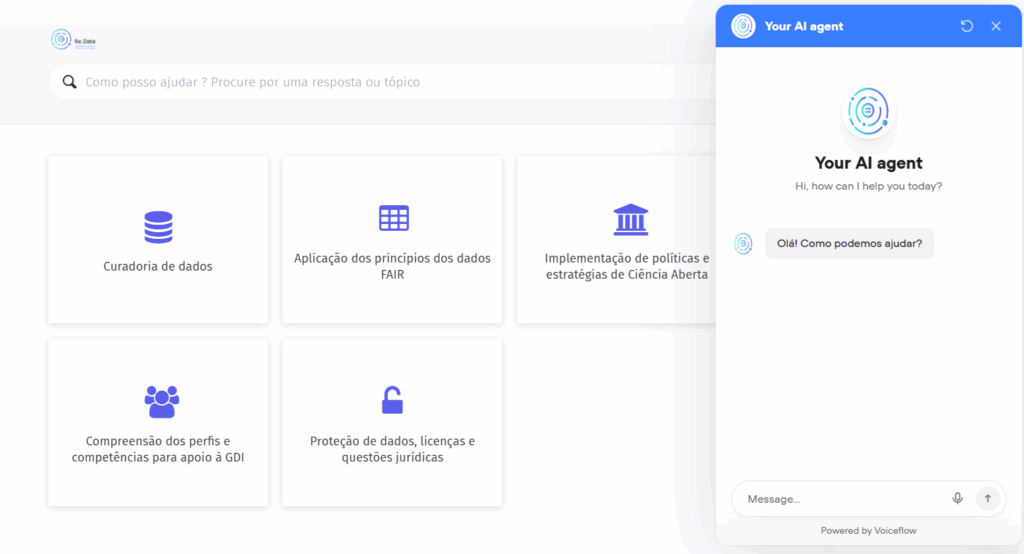
O serviço de helpdesk está acessível em https://redata.pt/helpdesk/ e é composto por três elementos principais: i) gestão de tickets de suporte, ii) base do conhecimento e iii) chatbot. Em conjunto, estes 3 elementos, oferecem o acesso rápido a respostas sobre práticas de gestão de dados e a possibilidade de colocar questões e obter resposta por parte de uma equipa de especialistas. Este serviço destina-se a quem desenvolve atividades de gestão de dados de investigação e necessitam de esclarecimento de dúvidas ou orientações sobre as melhores práticas a adotar.
Sistema de Helpdesk Re.Data
Gestão de Tickets de Suporte
Base do Conhecimento
Chatbot
Envio de pedidos por parte dos/as utilizadores/as com resposta de especialistas.
Acesso a documentação de apoio, como por exemplo perguntas frequentes.
Interação com um sistema de Inteligência Artificial (IA) que disponibiliza respostas às questões colocadas, tendo por base os conteúdos da base do conhecimento.
O serviço de gestão de tickets de suporte oferece funções básicas de receção de pedidos por parte dos utilizadores com resposta por parte de especialistas. Os utilizadores poderão colocar as suas questões utilizando o formulário online disponível na plataforma, sendo as interações posteriores realizadas por e-mail.
A base do conhecimento disponibiliza documentação de apoio à comunidade, no formato de perguntas frequentes (FAQs), estando categorizadas em 5 áreas: Aplicação dos princípios dos dados FAIR; Compreensão dos perfis e competências para apoio à GDI; Curadoria de dados; Implementação de políticas e estratégias de Ciência Aberta; Proteção de dados, licenças e questões jurídicas.
O utilizador pode navegar pelas categorias ou realizar uma pesquisa para encontrar as respostas pretendidas. Sempre que não encontrar a resposta pretendida, poderá contactar a equipa de suporte utilizando o sistema de tickets.
O chatbot é um interface conversacional baseado em inteligência artificial, que oferece aos utilizadores a possibilidade de colocarem questões e obterem respostas com base nos conteúdos da base do conhecimento. Esta funcionalidade está incorporada no portal do Re.Data, 24 horas por dia, sempre que seja necessário obter uma resposta rápida, estando acessível no canto inferior direito da página com o ícone.
Os conteúdos do sistema de helpdesk pretendem apoiar os utilizadores nas suas atividades de gestão de dados de investigação, contribuindo para o aprimoramento das melhores práticas na prática de gestão de dados.